COMPSs + Redis
COMPSs provides a built-in interface to use Redis as persistent storage from COMPSs’ applications.
Note
We assume that COMPSs is already installed. See Installation and Administration
The next subsections focus on how to install the Redis utilities and the storage API for COMPSs.
Hint
It is advisable to read the Redis Cluster tutorial for beginners 1 in order to understand all the terminology that is used.
COMPSs + Redis Dependencies
The required dependencies are:
Redis Server
redis-server is the core Redis program. It allows to create
standalone Redis instances that may form part of a cluster in the
future. redis-server can be obtained by following these steps:
Go to
https://redis.io/downloadand download the last stable version. This should download aredis-${version}.tar.gzfile to your computer, where${version}is the current latest version.Unpack the compressed file to some directory, open a terminal on it and then type
sudo make installif you want to install Redis for all users. If you want to have it installed only for yourself you can simply typemake redis-server. This will leave theredis-serverexecutable file inside the directorysrc, allowing you to move it to a more convenient place. By convenient place we mean a folder that is in yourPATHenvironment variable. It is advisable to not delete the uncompressed folder yet.If you want to be sure that Redis will work well on your machine then you can type
make test. This will run a very exhaustive test suite on Redis features.
Important
Do not delete the uncompressed folder yet.
Redis Cluster script
Redis needs an additional script to form a cluster from various Redis
instances. This script is called redis-trib.rb and can be found in
the same tar.gz file that contains the sources to compile
redis-server in src/redis-trib.rb. Two things must be done to
make this script work:
Move it to a convenient folder. By convenient folder we mean a folder that is in your
PATHenvironment variable.Make sure that you have Ruby and
geminstalled. Typegem install redis.In order to use COMPSs + Redis with Python you must also install the
redisandredis-py-clusterPyPI packages.Hint
It is also advisable to have the PyPI package
hiredis, which is a library that makes the interactions with the storage to go faster.
COMPSs-Redis Bundle
COMPSs-Redis Bundle is a software package that contains the
following:
A java JAR file named
compss-redisPSCO.jar. This JAR contains the implementation of a Storage Object that interacts with a given Redis backend. We will discuss the details later.A folder named
scripts. This folder contains a bunch of scripts that allows a COMPSs-Redis app to create a custom, in-place cluster for the application.A folder named
pythonthat contains the Python equivalent tocompss-redisPSCO.jar
This package can be obtained from the COMPSs source as follows:
Go to
trunk/utils/storage/redisPSCOType
./make_bundle. This will leave a folder namedCOMPSs-Redis-bundlewith all the bundle contents.
Enabling COMPSs applications with Redis
Java
This section describes how to develop Java applications with the
Redis storage. The application project should have the
dependency induced by compss-redisPSCO.jar satisfied.
That is, it should be included in the application’s pom.xml if you are
using Maven, or it should be listed in the
dependencies section of the used development tool.
The application is almost identical to a regular COMPSs application except for the presence of Storage Objects. A Storage Object is an object that it is capable to interact with the storage backend. If a custom object extends the Redis Storage Object and implements the Serializable interface then it will be ready to be stored and retrieved from a Redis database. An example signature could be the following:
import storage.StorageObject;
import java.io.Serializable;
/**
* A PSCO that contains a KD point
*/
class RedisPoint
extends StorageObject implements Serializable {
// Coordinates of our point
private double[] coordinates;
/**
* Write here your class-specific
* constructors, attributes and methods.
*/
double getManhattanDistance(RedisPoint other) {
...
}
}
The StorageObject object has some inherited methods that allow the
user to write custom objects that interact with the Redis backend. These
methods can be found in Table 23.
Name |
Returns |
Comments |
|---|---|---|
makePersistent(String id) |
Nothing |
Inserts the object in the database with the id.
If id is null, a random UUID will be computed instead.
|
deletePersistent() |
Nothing |
Removes the object from the storage.
It does nothing if it was not already there.
|
getID() |
String |
Returns the current object identifier if the object is not persistent (null instead).
|
Caution
Redis Storage Objects that are used as INOUTs must be manually updated.
This is due to the fact that COMPSs does not know the exact effects of
the interaction between the object and the storage, so the runtime cannot
know if it is necessary to call makePersistent after having used an
INOUT or not (other storage approaches do live modifications to its storage
objects). The followingexample illustrates this situation:
/**
* A is passed as INOUT
*/
void accumulativePointSum(RedisPoint a, RedisPoint b) {
// This method computes the coordinate-wise sum between a and b
// and leaves the result in a
for(int i=0; i<a.getCoordinates().length; ++i) {
a.setComponent(i, a.getComponent(i) + b.getComponent(i));
}
// Delete the object from the storage and
// re-insert the object with the same old identifier
String objectIdentifier = a.getID();
// Redis contains the old version of the object
a.deletePersistent();
// Now we will insert the updated one
a.makePersistent(objectIdentifier);
}
If the last three statements were not present, the changes would never
be reflected on the RedisPoint a object.
Python
Redis is also available for Python. As happens with Java, we
first need to define a custom Storage Object. Let’s suppose that we want
to write an application that multiplies two matrices 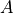 , and
, and
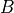 by blocks. We can define a
by blocks. We can define a Block object that lets us store
and write matrix blocks in our Redis backend:
from storage.storage_object import StorageObject
import storage.api
class Block(StorageObject):
def __init__(self, block):
super(Block, self).__init__()
self.block = block
def get_block(self):
return self.block
def set_block(self, new_block):
self.block = new_block
Let’s suppose that we are multiplying our matrices in the usual blocked way:
for i in range(MSIZE):
for j in range(MSIZE):
for k in range(MSIZE):
multiply(A[i][k], B[k][j], C[i][j])
Where and are Block objects and 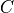 is a
regular Python object (e.g: a Numpy matrix), then we can define
is a
regular Python object (e.g: a Numpy matrix), then we can define
multiply as a task as follows:
@task(c = INOUT)
def multiply(a_object, b_object, c, MKLProc):
c += a_object.block * b_object.block
Let’s also suppose that we are interested to store the final result in our storage. A possible solution is the following:
for i in range(MSIZE):
for j in range(MSIZE):
persist_result(C[i][j])
Where persist_result can be defined as a task as follows:
@task()
def persist_result(obj):
to_persist = Block(obj)
to_persist.make_persistent()
This way is preferred for two main reasons:
we avoid to bring the resulting matrix to the master node,
and we can exploit the data locality by executing the task in the node where last version of
objis located.
C/C++
Unsupported
C/C++ COMPSs applications are not supported with Redis.
Executing a COMPSs application with Redis
Launching using an existing Redis Cluster
If there is already a running Redis Cluster on the node/s where the COMPSs application will run then only the following steps must be followed:
Create a
storage_conf.cfgfile that lists, one per line, the nodes where the storage is present. Only hostnames or IPs are needed, ports are not necessary here.Add the flag
--classpath=${path_to_COMPSs-redisPSCO.jar}to theruncompsscommand that launches the application.Add the flag
--storage_conf=${path_to_your_storage_conf_dot_cfg_file}to theruncompsscommand that launches the application.If you are running a python app, also add the
--pythonpath=${app_path}:${path_to_the_bundle_folder}/pythonflag to theruncompsscommand that launches the application.
As usual, the project.xml and resources.xml files must be
correctly set. It must be noted that there can be Redis nodes that are
not COMPSs nodes (although this is a highly unrecommended practice).
As a requirement, there must be at least one Redis instance on each
COMPSs node listening to the official Redis port 6379 2. This is
required because nodes without running Redis instances would cause a
great amount of transfers (they will always need data that must be
transferred from another node). Also, any locality policy will likely
cause this node to have a very low workload, rendering it almost
useless.
Launching on queue system based environments
COMPSs-Redis-Bundle also includes a collection of scripts that allow
the user to create an in-place Redis cluster with his/her COMPSs
application. These scripts will create a cluster using only the COMPSs
nodes provided by the queue system (e.g. SLURM, PBS, etc.).
Some parameters can be tuned by the user via a
storage_props.cfg file. This file must have the following form:
REDIS_HOME=some_path
REDIS_NODE_TIMEOUT=some_nonnegative_integer_value
REDIS_REPLICAS=some_nonnegative_integer_value
There are some observations regarding to this configuration file:
- REDIS_HOME
Must be equal to a path to some location that is not shared between nodes. This is the location where the Redis sandboxes for the instances will be created.
- REDIS_NODE_TIMEOUT
Must be a nonnegative integer number that represents the amount of milliseconds that must pass before Redis declares the cluster broken in the case that some instance is not available.
- REDIS_REPLICAS
Must be equal to a nonnegative integer. This value will represent the amount of replicas that a given shard will have. If possible, Redis will ensure that all replicas of a given shard will be on different nodes.
In order to run a COMPSs + Redis application on a queue system the user
must add the following flags to the enqueue_compss command:
--storage-home=${path_to_the_bundle_folder}This must point to the root of the COMPSs-Redis bundle.--storage-props=${path_to_the_storage_props_file}This must point to thestorage_props.cfgmentioned above.--classpath=${path_to_COMPSs-redisPSCO.jar}As in the previous section, the JAR with the storage API must be specified.If you are running a Python application, also add the
--pythonpath=${app_path}:${path_to_the_bundle_folder}flag
Caution
As a requirement, the supercomputer MUST NOT kill daemonized processes running on the provided computing nodes during the execution.