COMPSs + Hecuba

Hecuba is a set of tools and interfaces that implement a simple and efficient access to data stores for big data applications. The current implementation of Hecuba supports Python applications that store data in memory or Apache Cassandra databases.
The Hecuba manual is available in its Github Wiki.
Hecuba is developed by a team composed of BSC (Data-driven Scientific Computing research line) and UPC staff.

COMPSs + Hecuba Dependencies
The required dependency is Hecuba.
Download the Hecuba source code from the following repository: https://github.com/bsc-dd/hecuba.
And follow the instructions for the Hecuba Installation Procedure.
Enabling COMPSs applications with Hecuba
Java
Unsupported
Java COMPSs applications are not supported with Hecuba.
Python
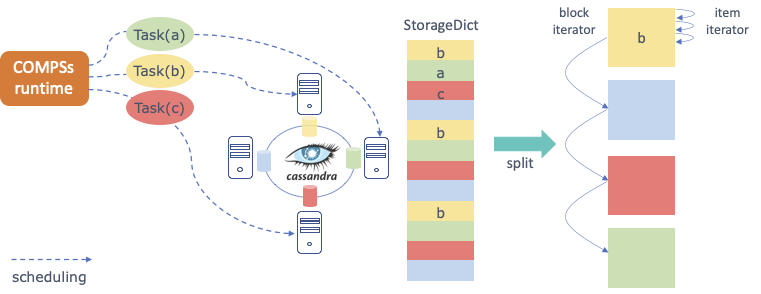
PyCOMPSs allow programmers to write sequential code and to indicate, through a decorator, which functions can be executed in parallel. The COMPSs runtime interprets this decorator and executes, transparent to the programmer, all the code necessary to schedule each task on a computing node, to manage dependencies between tasks and to send and to serialize the parameters and the returns of the tasks.
When input/output parameters of a tasks are persistent objects (i.e. their classes implement the Storage API defined to interact with PyCOMPSs), the runtime asks the storage system for the data locality information and uses this information to try to schedule the task on the node containing the data. This way no data sending or serialization is needed.
The following code shows an example of PyCOMPSs task. The input parameter of
the task could be an object resulting from splitting a StorageDict
(partition can be an object intance of MyClass that can be persistent).
In this example the return of the task is a Python dictionary.
from pycompss.api.task import task
from hecuba import StorageDict
class MyClass(StorageDict):
'''
@TypeSpec dict<<str>, int>
'''
@task(returns = dict)
def wordcountTask(partition):
partialResult = {}
for word in partition.values():
if word not in partialResult:
partialResult[word] = 1
else:
partialResult[word] = partialResult[word] + 1
return partialResult
C/C++
Unsupported
C/C++ COMPSs applications are not supported with Hecuba.
Executing a COMPSs application with Hecuba
Launching using an existing Hecuba deployment
If Hecuba is already running on the node/s where the COMPSs application will run then only the following steps must be followed:
Create a
storage_conf.cfgfile that lists, one per line, the nodes where the storage is present. Only hostnames or IPs are needed, ports are not necessary here.Add the flag
--classpath=${path_to_Hecuba.jar}to theruncompsscommand that launches the application.Add the flag
--storage_conf=${path_to_your_storage_conf_dot_cfg_file}to theruncompsscommand that launches the application.If you are running a python app, also add the
--pythonpath=${app_path}:${path_to_the_bundle_folder}/pythonflag to theruncompsscommand that launches the application.
As usual, the project.xml and resources.xml files must be
correctly set. It must be noted that there can be Hecuba nodes that are
not COMPSs nodes.
Launching on queue system based environments
To run a parallel Hecuba application using PyCOMPSs you should execute the
enqueue_compss command setting the options --storage_props and
--storage_home.
The --storage_props option is mandatory and should contain the path of
an existing file. This file can contain all the Hecuba configuration options
that the user needs to set (can be an empty file).
The --storage_home option contains the path to the Hecuba implementation
of the Storage API required by COMPSs.
Following, we show an example of how to use PyCOMPSs and Hecuba to run the python application in the file myapp.py.
compss job submit \
--num_nodes=4 \
--storage_props=storage_props.cfg \
--storage_home=$HECUBA_ROOT/compss/ \
--scheduler=es.bsc.compss.scheduler.lookahead.locality.LocalityTS \
--lang=python \
$(pwd)/myapp.py
In this example, we ask PyCOMPSs to allocate 4 nodes and to use the scheduler
that enhances data locality for tasks using persistent objects.
We assume that the variable HECUBA_ROOT contains the path to the
installation directory of Hecuba.
- Hecuba Configuration Parameters
There are several parameters that can be defined when running our application. The basic parameters are the following:
- CONTACT_NAMES (default value: ‘localhost’)
list of the Storage System nodes separated by a comma (example:
export CONTACT_NAMES=node1,node2,node3)- NODE_PORT (default value: 9042)
Storage System listening port
- EXECUTION_NAME (default value: ’my_app’)
Default name for the upper level in the app namespace hierarchy
- CREATE_SCHEMA (default value: False)
If set to True, Hecuba will create its metadata structures into the storage system. Notice that these metadata structures are kept from one execution to another so it is only necessary to create them if you have deployed from scratch the storage system.
- Hecuba Advanced Configuration Parameters
There are several parameters that can be defined for Hecuba configuration:
- NUMBER_OF_BLOCKS (default value: 1024)
Number of partitions in which the data will be divided for each node
- CONCURRENT_CREATION (default value: False)
You should set it to True if you need to support concurrent persistent object creation. Setting this variable slows-down the creation task so you should keep it to False if only sequential creation is used or if the concurrent creation involves disjoint objects
- LOAD_ON_DEMAND (default value: True)
If set to True data is retrieved only when it is accessed. If it is set to False data is loaded when an instance to the object is created. It is necessary to set to True if you code uses those functions of the numpy library that do not use the interface to access the elements of the numpy ndarray.
- DEBUG (default value: False)
If set to True Hecuba shows during the execution of the application some output messages describing the steps performed
- SPLITS_PER_NODE (default value: 32)
Number of partitions that generates the split method
- MAX_CACHE_SIZE (default value: 1000)
Size of the cache. You should set it to 0 (and thus deactivate the utilization of the cache) if the persistent objects are small enough to keep them in memory while they are in used
- PREFETCH_SIZE (default value: 10000)
Number of elements read in advance when iterating on a persistent object
- WRITE_BUFFER_SIZE (default value: 1000)
Size of the internal buffer used to group insertions to reduce the number of interactions with the storage system
- WRITE_CALLBACKS_NUMBER (default value: 16)
Number of concurrent on-the-fly insertions that Hecuba can support
- REPLICATION_STRATEGY (default value: ‘SimpleStrategy’)
Strategy to follow in the Cassandra database
- REPLICA_FACTOR (default value: 1)
The amount of replicas of each data available in the Cassandra cluster
- Hecuba Specific Configuration Parameters for the
storage_propsfile There are several parameters that can be defined for the
storage_propsfile for PyCOMPSs:- CONTACT_NAMES (default value: empty)
If this variable is set in the
storage_propsfile, then COMPSs assumes that the variable contains the list of of an already running Cassandra cluster. If this variable is not set in thestorage_propsfile, then theenqueue_compsscommand will use the Hecuba scripts to deploy and launch a new Cassandra cluster using all the nodes assigned to workers.- RECOVER (default value: empty)
If this variable is set in the storage_props file, then the
enqueue_compsscommand will use the Hecuba scripts to deploy and launch a new Cassandra cluster starting from the snapshot identified by the variable. Notice that in this case, the number of nodes used to generate the snapshot should match the number of workers requested by theenqueue_compsscommand.- MAKE_SNAPSHOT (default value: 0)
The user should set this variable to 1 in the storage_props file if a snapshot of the database should be generated and stored once the application ends the execution (this feature is still under development, users can currently generate snapshots of the database using the
c4stool provided as part of Hecuba).